Neue Funktion: Story Clustering
Simon
Ihr kennt das vielleicht: ein neues iPhone erscheint, ein neuer Papst wird gewählt oder Deutschland wird Fußballweltmeister. Das sind Ereignisse, über die berichten viele oder sogar alle deine abonnierten Feeds. Im Ergebnis siehst du dieselbe Nachricht fünf, zehn oder fünfzehn Mal in deiner Timeline. Jedes Mal mit leicht anderer Überschrift, anderem Einstieg, anderem Framing, aber derselben Substanz.
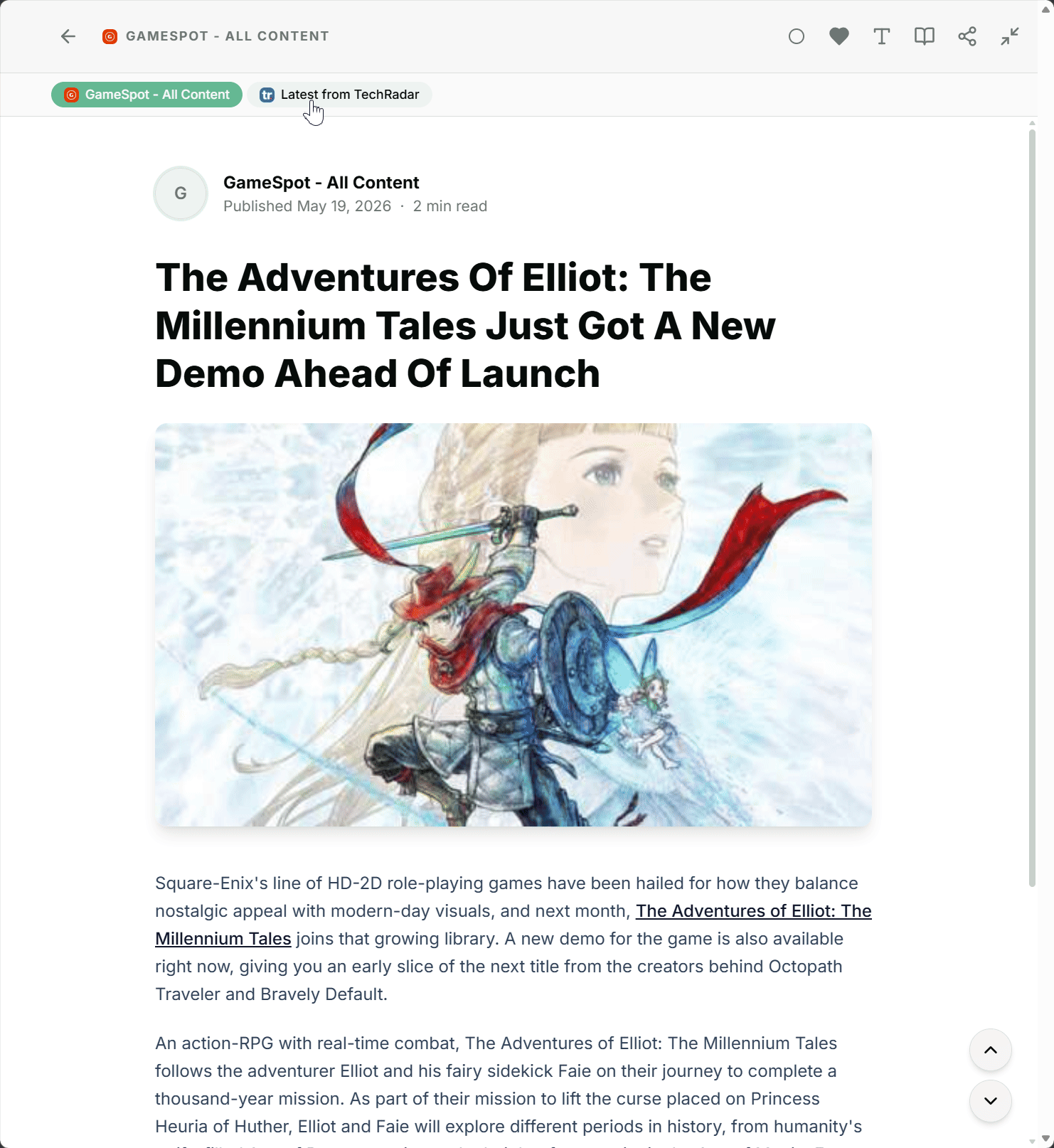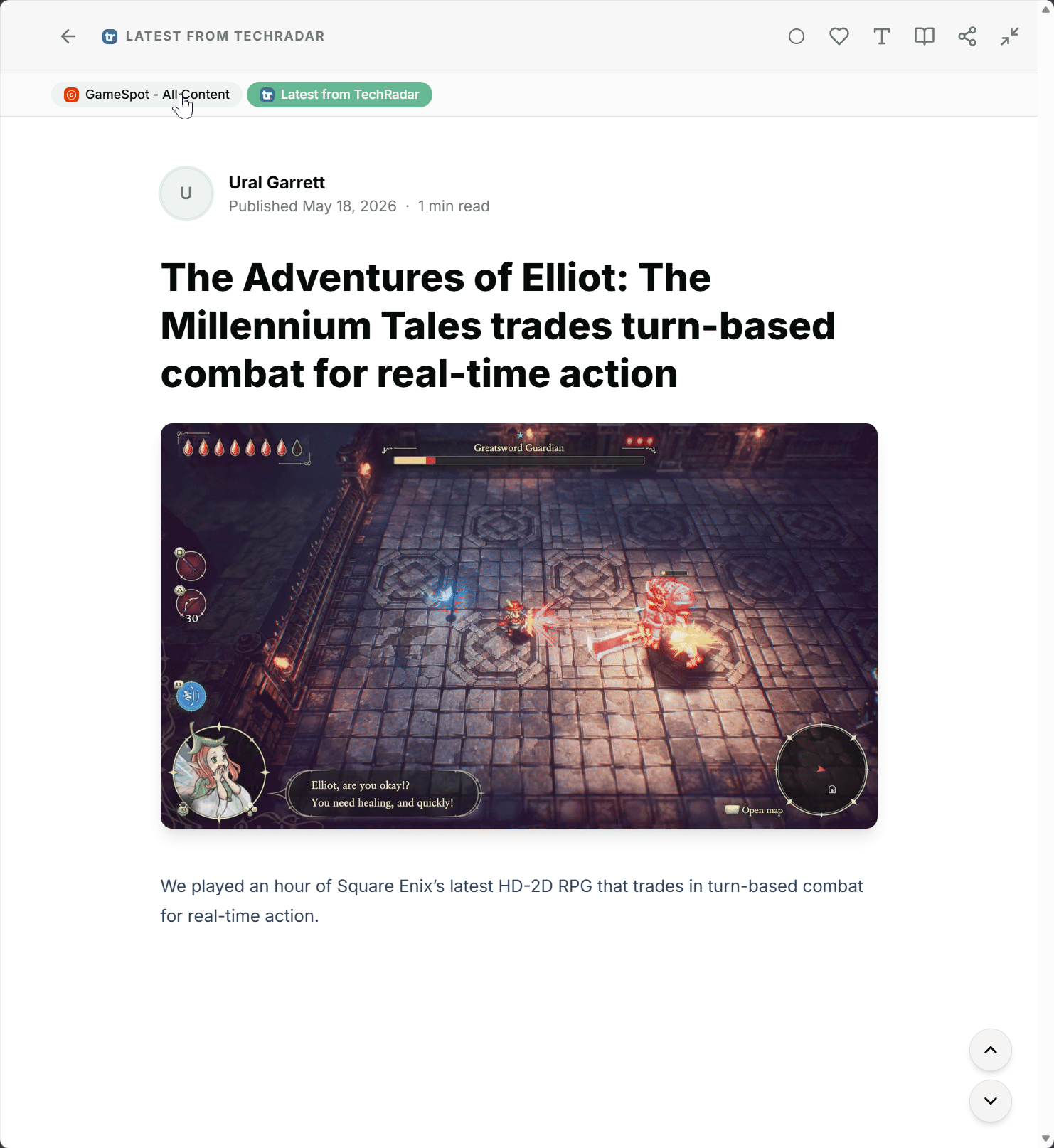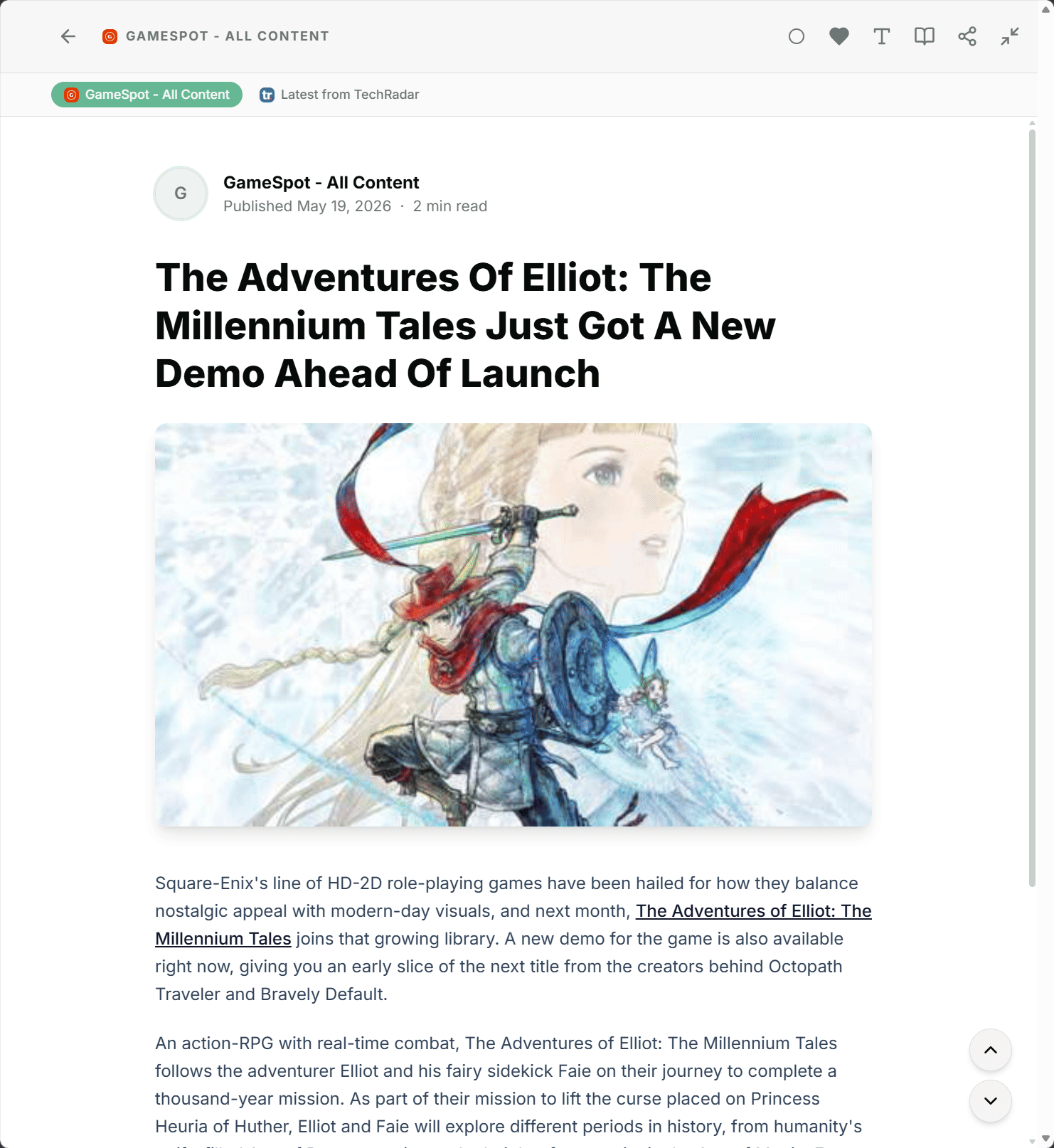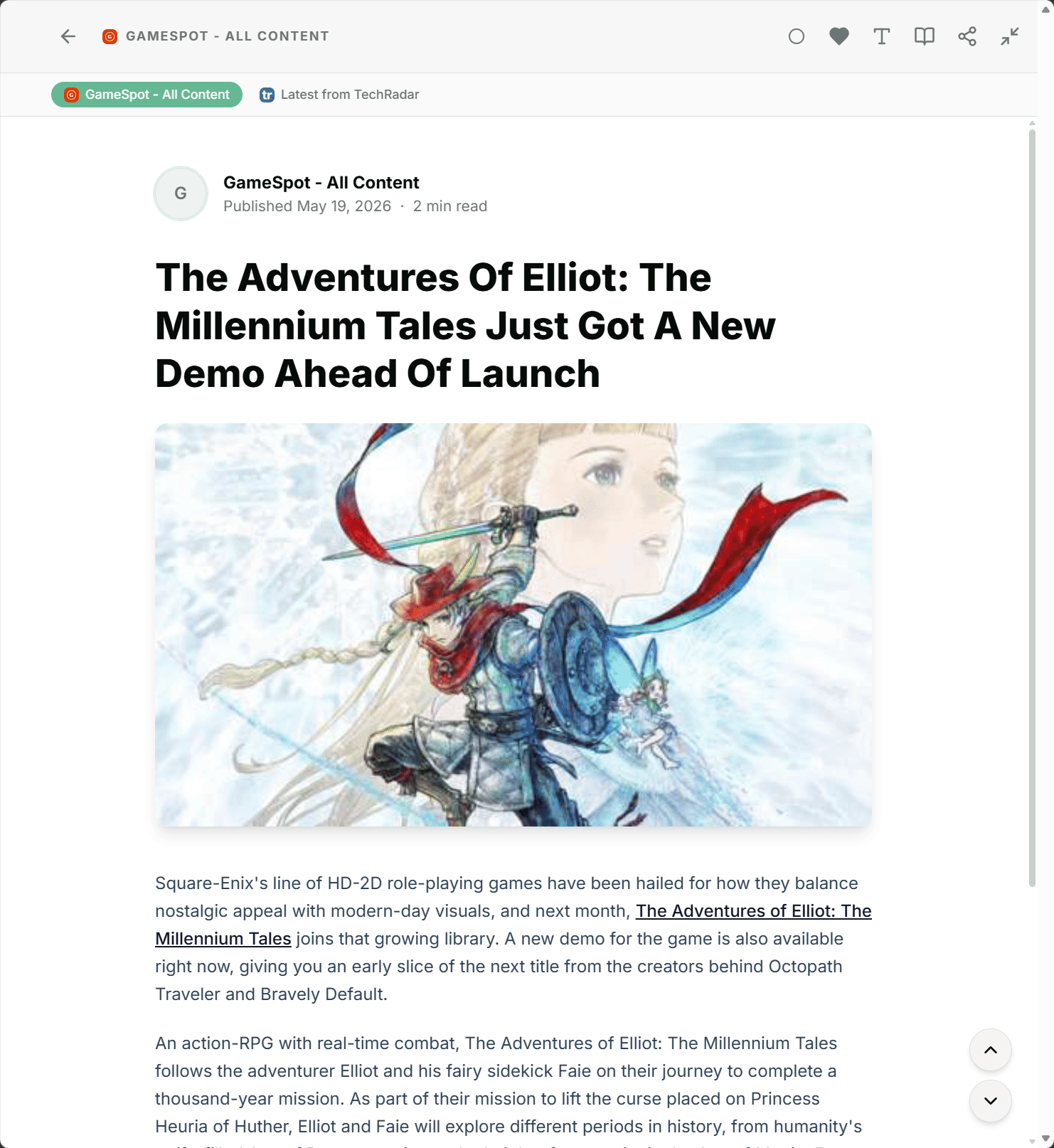
Mit der neuen Funktion Story Clustering bietet Feedlane für genau diesen Fall eine Lösung. Feedlane erkennt automatisch Artikel, die über dieselbe Story berichten, und fasst sie zu einem Cluster zusammen. In deiner Timeline taucht die Story nur einmal auf, mit einem Hinweis, dass es weitere Quellen zum selben Thema gibt.
![]()
Im Artikeldetail siehst du dann direkt, welche weiteren Feeds über das Thema berichten, und kannst, wenn du magst, mit einem Klick zwischen den Quellen wechseln. Manchmal lohnt sich der Vergleich der Perspektiven, manchmal reicht dir die eine Version. Du entscheidest.
Markierst du den Hauptartikel als gelesen, werden alle anderen Artikel im Cluster ebenfalls als gelesen markiert. Umgekehrt nicht: wenn du einen einzelnen Artikel wieder auf ungelesen setzt, bleiben die anderen unverändert. Wer eine Quelle nochmal lesen will, soll dafür nicht die anderen zurückbekommen.
Story Clustering ist standardmäßig ausgeschaltet. Aktivieren kannst du die Funktion unter Einstellungen › Allgemein › Story Clustering. Dort kannst du außerdem bevorzugte Quellen festlegen. Artikel aus diesen Feeds werden dann bevorzugt als Hauptartikel verwendet, wenn sie Teil eines Clusters sind. Ohne diese Vorgabe entscheidet Feedlane anhand der Inhaltslänge: der Artikel mit dem ausführlichsten Inhalt gewinnt.
Suche, Leselisten, Smart Lists und Apps von Drittanbietern (Fever API) zeigen weiterhin alle Einzelartikel.
Wie das technisch läuft
Feedlane erkennt ähnliche Stories über semantische Embeddings. Statt Wörter oder Überschriften direkt zu vergleichen, übersetzt Feedlane jeden eingehenden Artikel in eine mathematische Repräsentation seiner Bedeutung. Konkret bekommt jeder Artikel (Titel plus Zusammenfassung) durch ein mehrsprachiges Sentence Transformer Modell namens paraphrase-multilingual-MiniLM-L12-v2 einen Vektor mit 384 Dimensionen zugeordnet. Vereinfacht gesagt: ein Punkt in einem Raum mit 384 Dimensionen, dessen Position die Bedeutung des Textes widerspiegelt.
Zwei Artikel, die inhaltlich dasselbe sagen, landen in diesem Raum dicht beieinander, auch wenn sie unterschiedliche Wörter verwenden oder in unterschiedlichen Sprachen geschrieben sind. „Apple stellt neues iPhone vor" und „Apple unveils new iPhone" liegen praktisch übereinander, eine Meldung zu einem Bundesligaspiel dagegen weit weg. Genau diese Nähe nutzt Feedlane, um zu entscheiden, ob zwei Artikel über dieselbe Story berichten.
Wird ein neuer Artikel verarbeitet, vergleicht Feedlane sein Embedding mit allen Clustern, in die innerhalb der letzten 12 Stunden ein Artikel eingegangen ist. Ist die Nähe ausreichend, wandert der Artikel in den passenden Cluster und erscheint dort als zusätzliche Quelle. Ansonsten startet er einen neuen Cluster, an den sich später weitere Artikel anhängen können. Cluster, in die seit mehr als 12 Stunden nichts mehr eingegangen ist, werden geschlossen und nicht weiter erweitert. Spätere Artikel zur selben Story bilden dann eine eigene neue Story. Das stellt sicher, dass die Zusammenfassung auf den aktuellen Nachrichtenstrom bezogen bleibt und nicht beliebig viele Tage zurück Stories nachträglich verkettet werden.