New Feature: Story Clustering
Simon
You probably know this situation: a new iPhone gets announced, a new pope is elected, or Germany wins the World Cup. These are events that many of your subscribed feeds cover, sometimes all of them. The result: you see the same story five, ten, fifteen times in your timeline. Slightly different headlines, different leads, different framing, but the same substance.
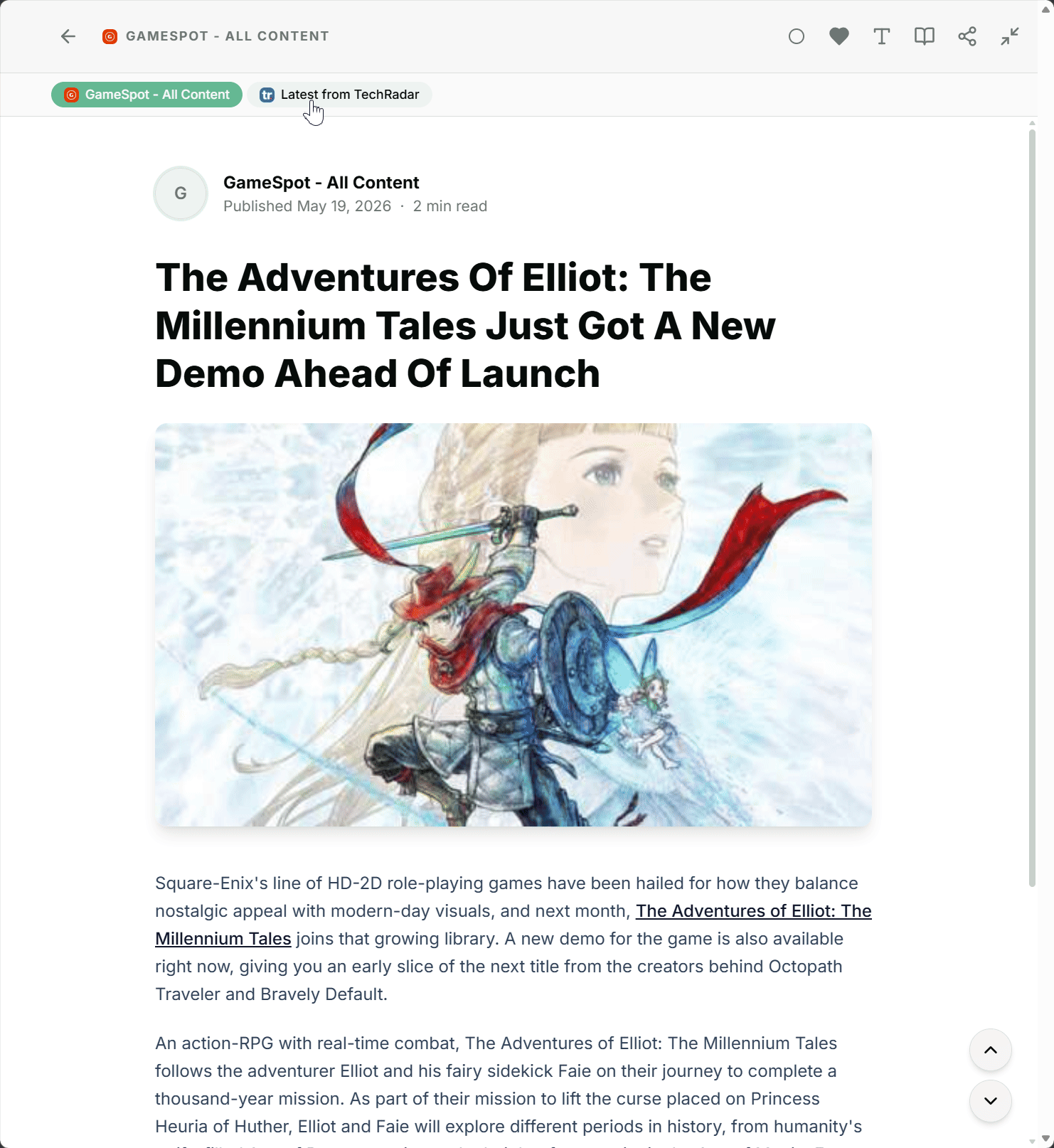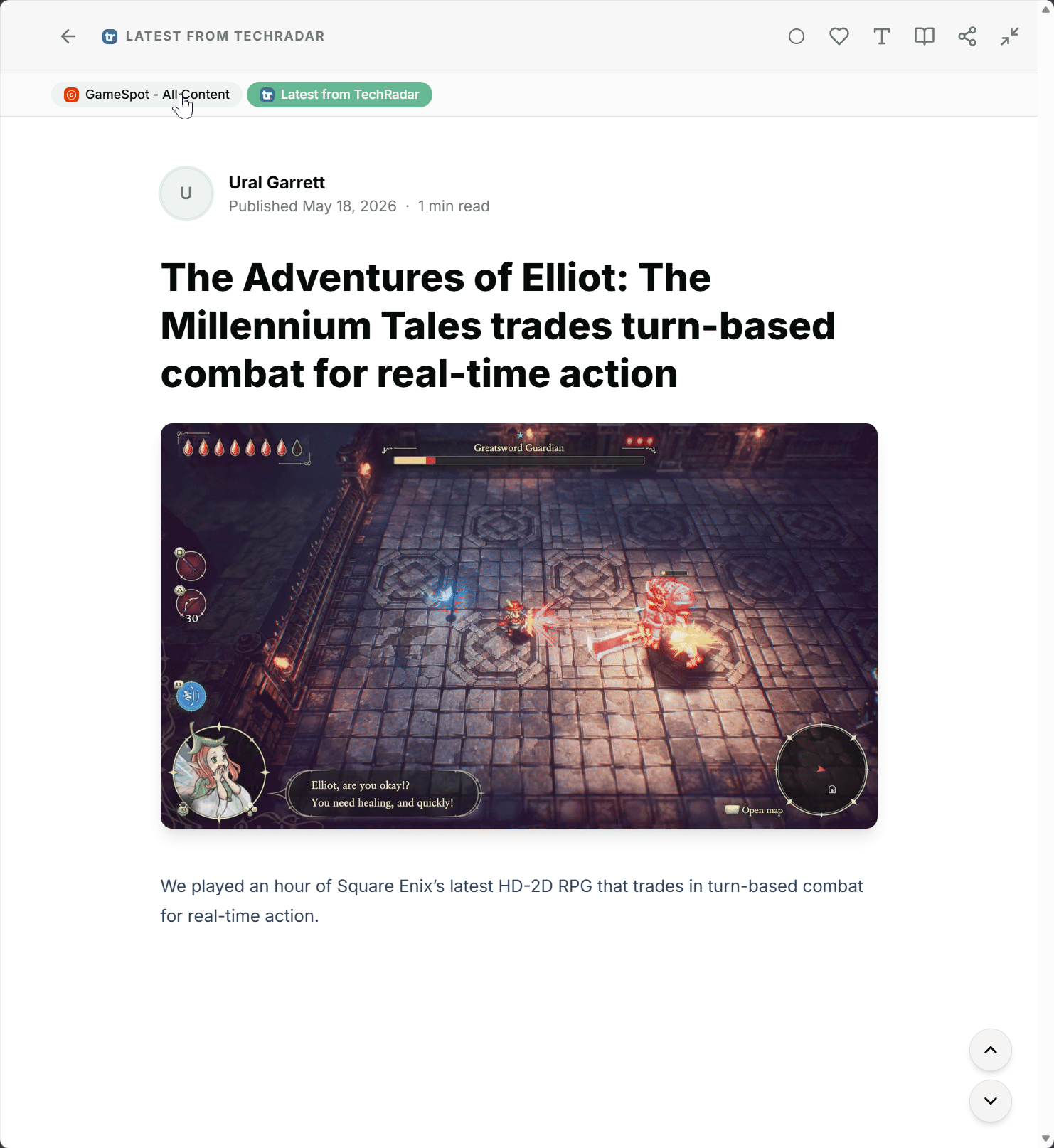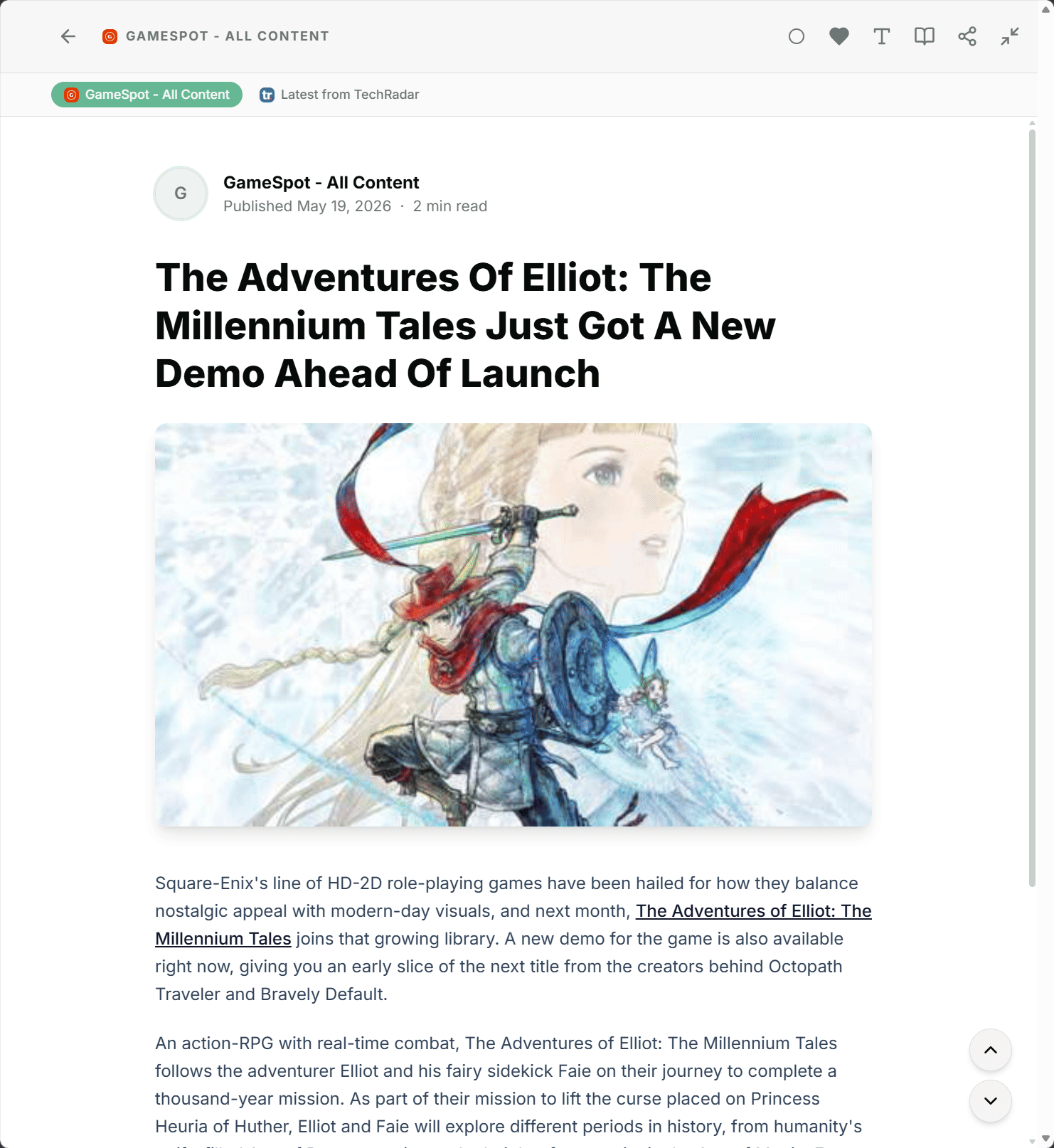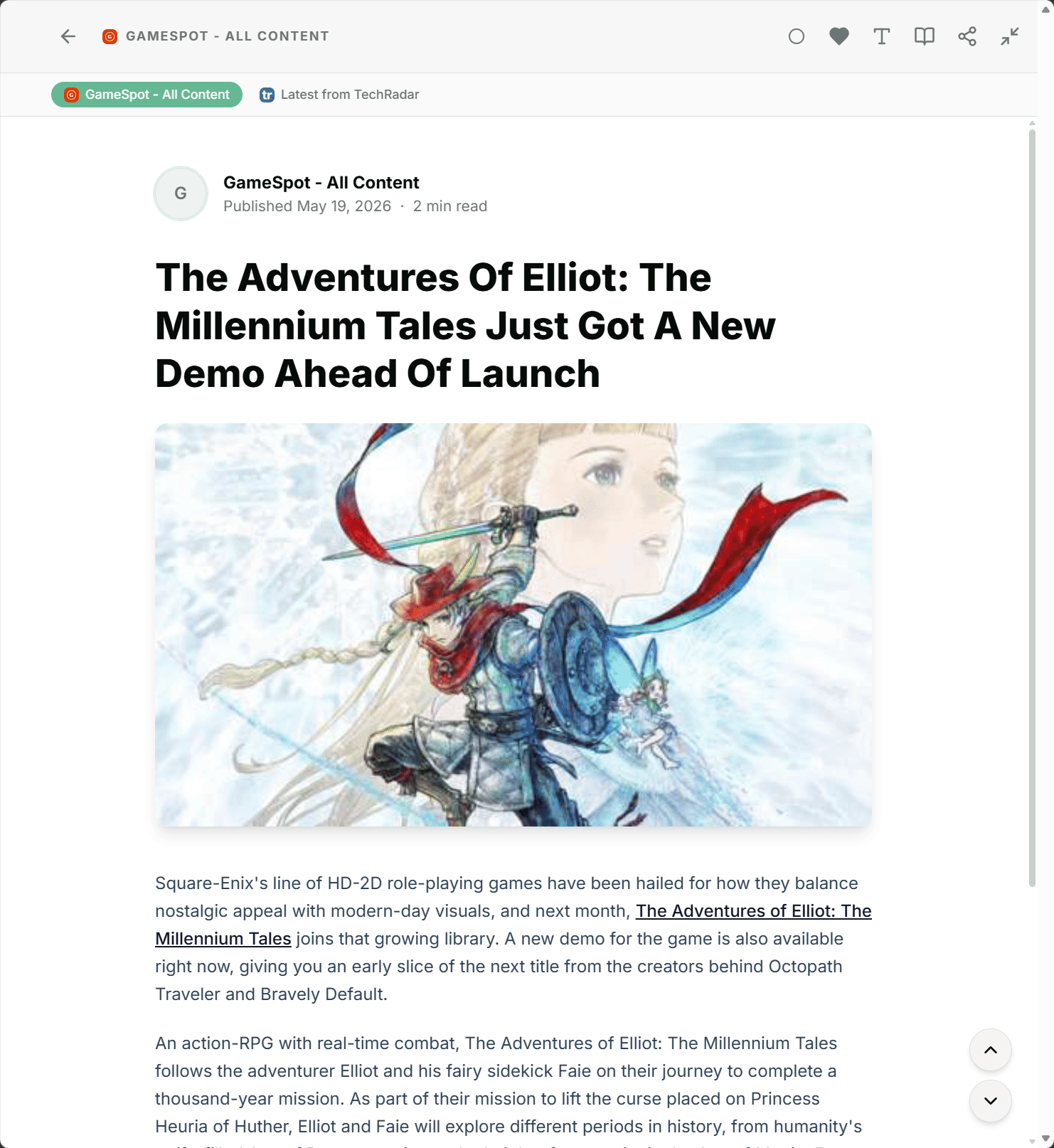
The new Story Clustering feature in Feedlane is built for exactly this case. Feedlane automatically detects articles that cover the same story and groups them into a single cluster. In your timeline, the story shows up only once, with a hint that there are more sources covering the same topic.
![]()
Inside the article detail, you can see which other feeds cover the same story and switch between sources with a click, if you want. Sometimes it's worth comparing perspectives, sometimes one version is enough. Your call.
When you mark the primary article as read, every other article in the cluster gets marked as read too. The reverse isn't true: if you unread a single source, the others stay as they were. Re-reading one angle shouldn't resurface the others.
Story Clustering is off by default. You can enable it under Settings › General › Story Clustering. There you can also set your preferred sources. Articles from those feeds are then preferred as the primary whenever they're part of a cluster. Without a priority set, Feedlane picks by content length: the article with the most substantial content wins.
Search, reading lists, smart lists, and third party apps (Fever API) still show every individual article.
How it works under the hood
Feedlane detects similar stories using semantic embeddings. Instead of comparing words or headlines directly, every incoming article gets translated into a mathematical representation of its meaning. Concretely, each article (title plus summary) is run through a multilingual sentence transformer model called paraphrase-multilingual-MiniLM-L12-v2, which produces a vector with 384 dimensions. Put simply: a point in a space with 384 dimensions whose position reflects what the text is about.
Two articles that say the same thing end up close together in that space, even if they use different words or are written in different languages. "Apple unveils new iPhone" and "Apple stellt neues iPhone vor" sit on top of each other, while a soccer match report lands far away. That spatial closeness is what Feedlane uses to decide whether two articles cover the same story.
When a new article is processed, Feedlane compares its embedding against every cluster that received an article within the last 12 hours. If the closeness is sufficient, the article joins that cluster and appears there as an additional source. Otherwise it starts a fresh cluster that later articles can attach to. Clusters that haven't received anything for more than 12 hours are closed and no longer extended. Later articles on the same story then form a new story of their own. That keeps the grouping tied to the current news stream and prevents days old stories from getting retroactively merged with new coverage.